January 11, 2026

We've been building Tusk Drift, an open-source testing tool that records and replays live traffic to find regressions. Think of this as a Postman Collection that's automatically created and maintained based on user interactions with your service.
To record traces that include request/response bodies, we create instrumentation (similar to OpenTelemetry's) for libraries like Postgres, MySQL, and Redis. Each time we add instrumentation for a new library, we write tests to verify that it works. Being a testing company ourselves, we try to be exhaustive in our testing but––being human––we aren't able to think of every possible execution path.
I had an idea: what if we could use Claude Code to proactively hunt for bugs in our instrumentation?
So I decided to let Claude Code run in the background. It would poke around in the SDK repo, try different call patterns, and exercise methods we forgot to test. Naturally, it ended up generating a bunch of hypotheses about potential bugs.
Some examples of threads it would dive into:
null here?"Great, but now we have a different problem. Out of the dozens of hypotheses generated, how do we know which of them are actually bugs?
It’s common knowledge now that LLMs are really good at generating a confident-sounding list of issues. A few will be real, while a good amount will be false positives. And then there are some that are technically possible but may only happen in some sort of black swan event.
This is why a lot of surface-level "AI finds bugs" demos don't translate to actual workflows in production. The AI exploration part is easy. The verification part is where it falls apart.
The first step of building this true AI developer then was to narrow the possibilities of its own thinking. Otherwise, we were trading one problem for another by adding a workflow step that was almost as tedious as the original.
What worked for us was building e2e test infrastructure that could deterministically verify whether something was actually a bug.
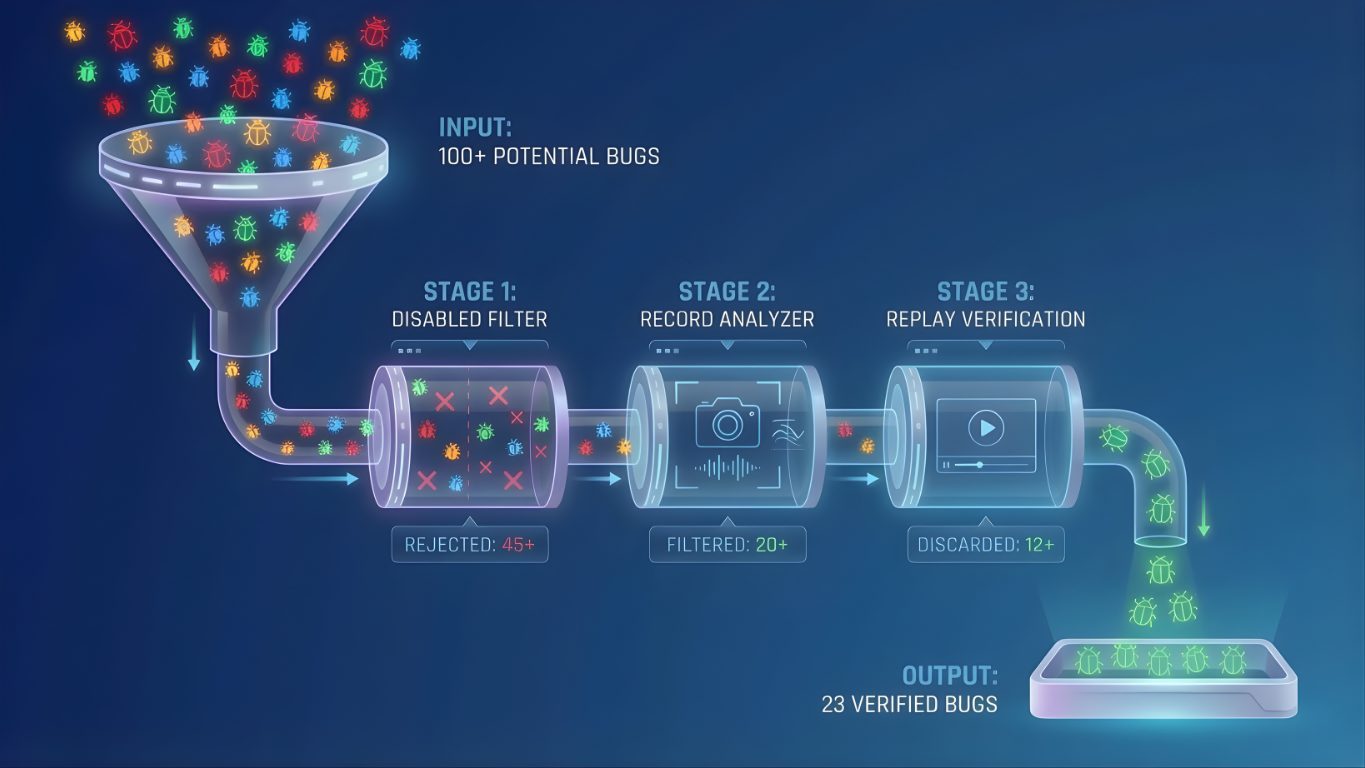
We run our tests in three modes:
DISABLED → RECORD → REPLAY
Each mode answers a specific question:
If a test passes in “Disabled” but fails in “Record”, our instrumentation broke something. If it passes in “Record” but fails in “Replay”, we didn't capture traffic correctly. If it fails in “Disabled”, the test itself is broken and should be disregarded.
The outcomes are binary, which means there's no room for subjective interpretation.
Now Claude Code can generate as many hypotheses as it wants, and the verification system filters out the noise automatically.
I gave Claude Code a structured workflow:
Phase 1: Understand the codebase
Read the instrumentation code, the package we're instrumenting, and existing tests
Phase 2: Generate hypotheses
Get the agent to poke around and ask questions like:
Phase 3: Test each hypothesis
For each potential bug:
Phase 4: Document immediately
After each test, update a BUG_TRACKING.md file with the results. This creates an audit trail on an ongoing basis and prevents Claude Code from forgetting what it's tested.
At the same time, we provide instruction to Claude Code to only keep test endpoints that found actual bugs in its changes. Remove all others to prevent bloat.
Phase 5: Fix confirmed bugs
For any confirmed bug in BUG_TRACKING.md, start a separate agent conversation with the context from the markdown file and failing e2e test that surfaced the bug.
Have Claude Code generate a fix, re-run the e2e test, look at the test execution output and iterate if the test still isn’t passing. Do this for each confirmed bug until the e2e test is passing.
Let me show you what this looks like in practice.
Claude Code was analyzing our Postgres instrumentation. It read through the Postgres library source code and noticed that queries can accept a rowMode parameter. When set to 'array', Postgres returns results as arrays instead of objects:
// Normal mode returns objects
// result.rows = [{ id: 1, name: 'John', email: 'john@example.com' }]
// rowMode: 'array' returns arrays
// result.rows = [[1, 'John', 'john@example.com']]
Claude Code generated a hypothesis: "What if users specify rowMode: 'array' in their queries?" It wrote a test endpoint for our SDK:
// Test endpoint for query with rowMode: 'array'
if (url === "/test/query-rowmode-array" && method === "GET") {
const result = await client.query({
text: "SELECT id, name, email FROM test_users WHERE id = $1",
values: [1],
rowMode: "array",
});
res.writeHead(200, { "Content-Type": "application/json" });
res.end(
JSON.stringify({
success: true,
data: result.rows,
rowCount: result.rowCount,
queryType: "query-rowmode-array",
}),
);
return;
}Disabled mode: ✅ Endpoint works fine, returns arrays as expected
Record mode: ✅ Endpoint runs without errors, traces captured
At this point, you might assume there's no bug. The code runs successfully with instrumentation and we're capturing traffic. However, when in replay mode, Claude Code found a data format mismatch.
Instead of getting:
[[1, 'John', 'john@example.com']]
The application received:
[{ '0': 1, '1': 'John', '2': 'john@example.com' }]i.e., objects with numeric keys instead of arrays. The bug is confirmed.
The agent then helped push a fix (PR #79) that made three changes:
rowMode parameter when parsing queriesrowMode through to our type conversion logicThe type conversion logic now checks rowMode and processes rows accordingly:
// If rowMode is 'array', handle arrays differently
if (rowMode === 'array') {
// For array mode, rows are arrays of values indexed by column position
const convertedRows = result.rows.map((row: any) => {
if (!Array.isArray(row)) return row; // Safety check
return row.map((value: any, index: number) => {
const field = result.fields[index];
if (!field) return value;
return this.convertPostgresValue(value, field.dataTypeID);
});
});
return {
...result,
rows: convertedRows,
};
}
This is the type of subtle bug that's easy to miss. Our existing tests all used the default object mode. They passed. But any user specifying rowMode: 'array' would get incorrect data during replay.
Without the verification system, Claude Code would have generated the hypothesis "what if they use rowMode: 'array'?" and I might think, "Well, we're capturing the query results, so that should work." The hypothesis would seem unnecessary. With the verification system, there's no debate that the data format was wrong. The bug is real.
Having an AI developer work 24/7 trying to break your code always felt like a pipe dream. So it’s really cool to see that some semblance of this is possible today.
We've tested this workflow across multiple libraries now. Claude Code, when used this way, reminds me of a senior engineer who thinks systematically about edge cases, triages with precision, and tests rigorously before claiming victory.
This pattern generalizes beyond our SDK’s instrumentation. The core idea is that AI generates hypotheses while systems verify truth.
Here's what you need:
1. A way to express potential bugs as tests
Can you write code that exercises the potential bug? For us, those are e2e test endpoints. For you, it might be unit tests, integration tests, or something else.
2. Multiple modes or branches that reveal bugs
For us, the modes are disabled/record/replay. For you, the modes might be:
The key is having at least two modes where bugs manifest differently.
3. Binary outcomes
Each verification step needs a clear, objective pass/fail. "The test crashed" is binary. "The output seems weird" –– not so much.
4. Incremental documentation
Don't wait until the end to document a summary of the agent’s findings. After each test, get the agent to write down what happened. This keeps the agent on track and creates an audit trail for it (and you) to review.
Across 12 libraries, we found and resolved 23 bugs using this Claude Code workflow. Bugs included things like:
Claude Code tested 100+ hypotheses total. That means it generated a ton of false positives. Still, without the verification system, I'd be manually investigating all 100 odd hypotheses. With it, I know the 23 are real and the remainder aren't worth my time.
In the last 8 months, a lot of attention has shifted from human-in-the-loop towards background agents like OpenAI Codex and Google Antigravity performing long-running tasks.
What has been undervalued, however, is the design of smart feedback loops and exit conditions that enable your coding agents to be creative while reaching objective truths autonomously.
As with most coding agents, Claude Code is great at generating hypotheses. It thinks of edge cases and explores exhaustively in a way that humans can’t. But distinguishing real bugs from hallucinated ones is where it still struggles.
Your verification system doesn't need to be fancy. Ours relies on running e2e tests in three different modes. The most important thing is for it to be deterministic and binary.
Build the system that says "yes" or "no." Then let AI work within it.
---
About Tusk: Tusk is an AI-powered unit/integration testing platform that allows engineering teams to ship changes confidently, even in the age of AI.
Our core product, Tusk Drift, auto-records live traffic and replays traces as deterministic tests to find regressions. For that to work, our SDK’s instrumentation needs to handle every edge case. This debugging workflow is how we ensure quality at scale.
Try it yourself at usetusk.ai or check out our open-source SDK. Stars ⭐ and contributions welcome.

